
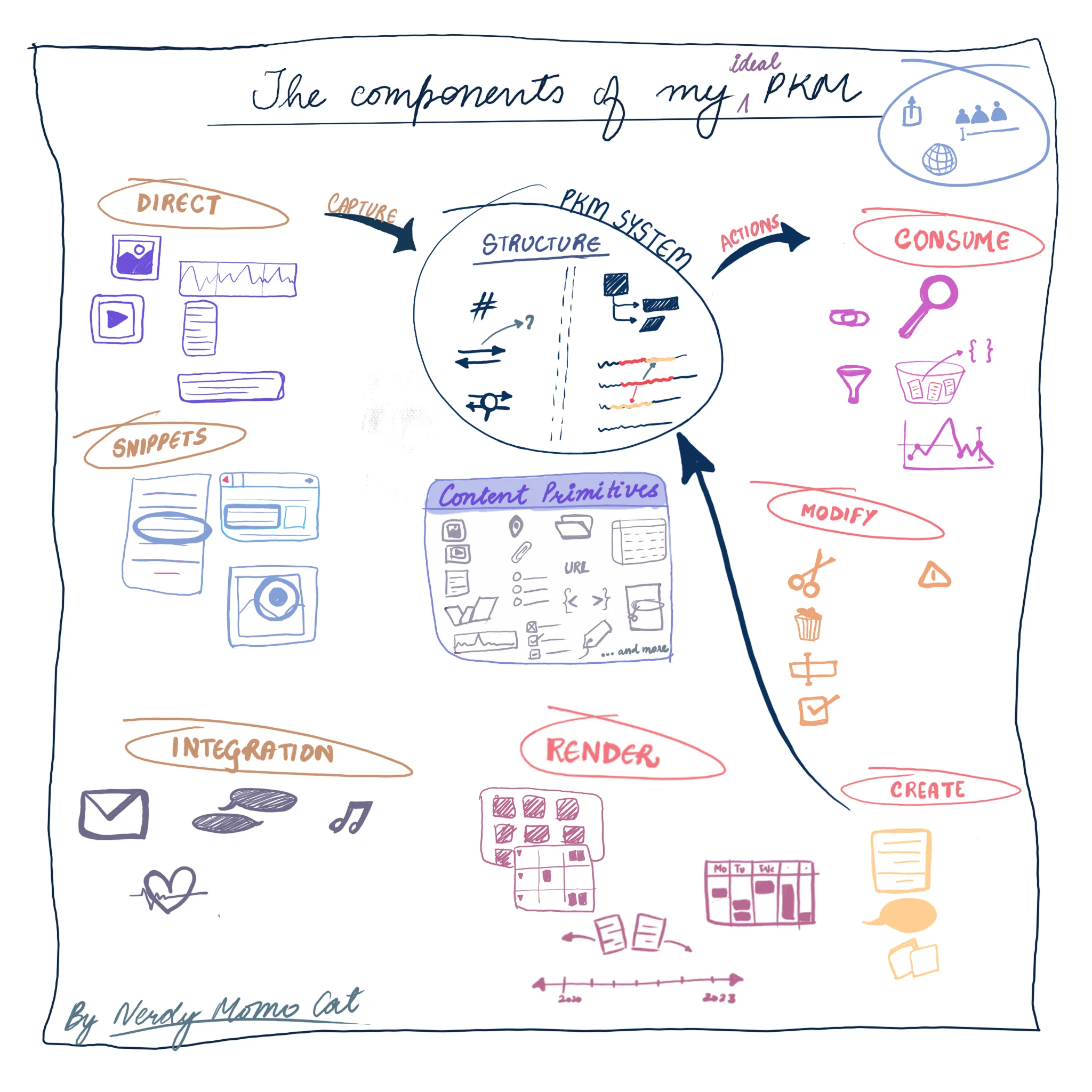
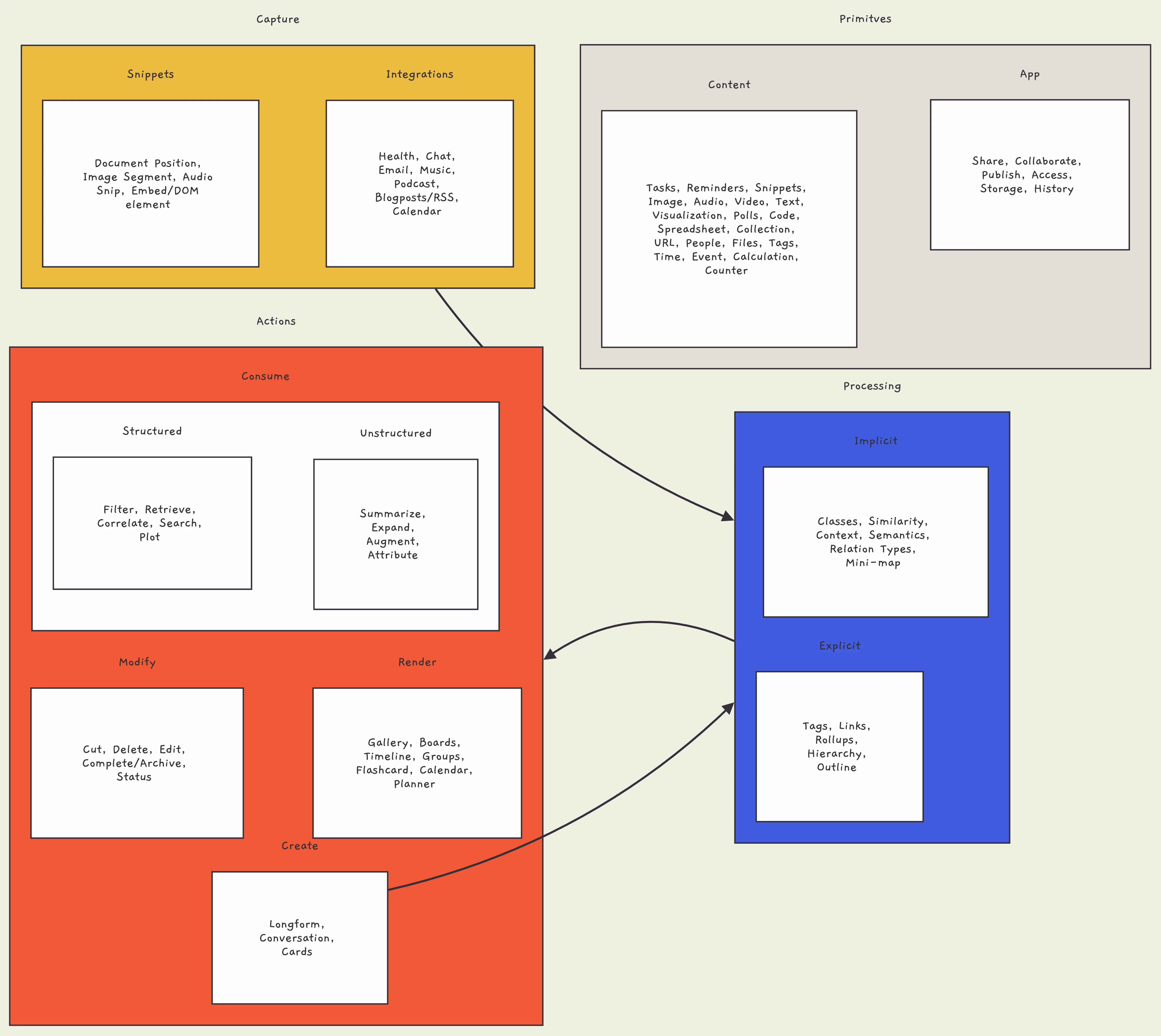
Personal Knowledge Management (PKM) involves capturing, processing, and taking actions on information. App primitives and content primitives are the building blocks of PKM systems. Integrations and snippets are two types of capture methods, with integrations pulling data from other apps and snippets being direct input. Processing can be explicit (manual organization) or implicit (background processing by the PKM). Actions, such as creating and consuming content, are how users interact with the PKM. Rendering structures the information for easy access, while modification allows for changes and updates. AI can enhance PKM by providing context, recognition and automation to improve the efficiency and effectiveness of the PKM system.
Personal Knowledge management has remained a subject of discussion since ages. One of the most common way people manage their personal knowledge is spread across email, drive and notes apps. Most people end up using google docs, apple notes, or google keep as a starter. If they want to do something more complicated, they end up with something like Evernote or OneNote. Add another level of complexity and you end up with something similar to Notion, Tana etc. No matter the app chosen and the management philosophy, it all boils down to primitives, capture, processing and actions. So this post is a generalized discussion of these components. I also talk about how AI can contribute or interact with these components in short and long term.
Understanding the PKM Primitives
Primitives in my viewpoint are the basic building blocks of any system. In this case we are talking about personal knowledge management systems. Building blocks usually have 2 characteristics: they can be combined to build more complex systems; and they can be used to define the possibilities or infrastructure of any system.
.B3XjDilF_Z1cRtqu.webp)
App Primitives
App primitives, in my viewpoint are the capabilities or possibilities of a system. These are often implemented on a backend level and not on a content level. It does not matter what the content is, app primitives are most content-agnostic. Some common examples of these are share, collaboration. permissions, history etc. These apply to any content that is present in the app. This is also an implementation that many people are divisive over. For example files over app is a philosophy that is still relevant to app primitives, just that the storage is plaintext or markdown files.
Content Primitives
Content primitives are smaller building blocks that can combine together to create better or more complex systems. Content primitives define a set of actions associated to those “blocks” as well. the content primitives defined above should cover most cases, but one of the best abilities that an app can provide is creating new content primitives specific to the user, such as Notion or Tana. One of the missing aspect for all of these content primitives is default actions and default recognition. For example, task is a common content primitive in many apps — the idea there being that it has at least two states of not done vs done. Or a timestamp has a “change date” action. But there is a dire dearth of content primitives recognized by apps.
The Art of Capture
Capture is a largely unsolved problem. Every time a new capture app comes into picture; there is a reason why everyone is so excited. Capture has many problems to overcome → it has to be quick, it should be in context, it has to work offline, it has to work with multiple modes. Capture can be classified into two categories →capture from integrations or basically data input into a different app that is then pulled into your personal knowledge management system. Snippets on the other hand are content that is meant to be as a direct input into the knowledge system.
.Bi_pS4W5_Z29gp4u.webp)
Integrations
Integrations refer to the general idea of having different apps that are specialized; to be later fed into your personal knowledge management system There can be multiple integrations that people have — the most common ones being chat and email. No one expects to be talking through their personal knowledge system (unless you are Google Chat and Spaces), but having integrations ensures that you still get the best experience for the particular component.
Integrations tie into various aspects of content primitives. For example, an email integration ideally integrates with person, text and files primitives. The special aspect of any great app is this idea of integration being automated through LLMs or AI; converting this unstructured data input into structured tags or relations with the baseline or user defined content primitives.
Snippets
Snippets are direct input of data. These can either be standalone snippets — for example that note you create about your partner, or can be positioned snippets. Positioned snippets tie back into the content primitives, that is, you have a particular kind of content, their position.
There are certain aspects of snippets that are best helped by AI. Consider standalone snippets. OCR, transcription, object recognition are some basic actions that can be performed on these snippets to improve the utility of a PKM. For positioned snippets, something that extracts context and embeds the context within the the captured input is possibly the north star of utility for a PKM app. You want a house in a meme vs house on a street show up in the same context during search or filtering.
Unlocking Knowledge Through Processing
.CmzBNUVB_1yJmvu.webp)
Explicit Processing
Explicit processing refers to the idea of a person manually organizing the content in their PKM in a way that best makes sense. There are multiple ways this kind of processing is facilitated; for example, in the very basic apps, tags and folders are the most prominent methods of explicit processing. Bear and obsidian support hierarchical tags and that improves the kind of organization an app can provide. More complex apps provide linking between “snippets”, rolling up associated information, table of contents as possible processing of the input content.
Implicit Processing
Implicit processing on the other hand is something that a PKM performs in the background. Most apps that exist at the moment have none or barely existent implicit processing. Let’s try an analogy to understand what the very basic ideas of implicit processing is. — “Oh you open google keep everytime you come back from this location” or “It seems like you are not home. Should I turn off all lights” is a self inferred rule by an operating system or through a smart home system. For PKM, this can look like — oh, we create this scrollable mini map on the side that extracts the main theme/idea from each paragraph. Implicit processing is what makes any app seem seamless. While you can go along a fair bit with handcrafted rules, the best implicit processors are guided structuring processes that align with a user’s desired behavior and still run in the background.
Actions - The Grand Finale
Actions, as I speak of, are interactions that can occur with or on the data that is stored in a PKM. Actions define how you use the system that you are engaging with. Actions can occur not only on a singular snippet but on a combination of them. Actions and processing are also the key differentiators between choosing different applications.
.CdrwaFoO_Z1zQoX9.webp)
Create
Creating is one of the primary actions that everyone here probably identifies with. Whether you are a content creator or not, creation of notes, long form content, sharing a set of snippets in a post, a listicle, creating easily glanceable information, creating a website, creating a repository, all of forms of creation actions. Creating directly feeds back into processing, given how it is at direct user-level interaction. It is an active action (funny, how active should usually imply actions anyway).
Consume
Consumption is usually the other side of coin for primary actions. Consumption though is a passive action. This hence, does not usually correlate with explicit processing. Learning the behavior of consumption though is a huge deal of processing — for example, if you look up “house”, what do you want to come up in search. This is mostly a form of data log modelling, and beyond the scope of this post.
Structured
Structured consumption in my perspective refers to a retrieval based action. This can be structured in either its attributes that can be used to filter or correlate, to search or bring up related to information or snippets, plot information on a graph for two related variables etc. I use the word structure specifically to refer to something that has no creation of information. The information all exists and is surfaced as needed.
Unstructured
Unstructured consumption in my opinion is when the app does some kind of synthesis of information. This can be as basic as synthesizing the summary of the snippet (as Notion AI and a million other PKM apps do), can be summarizing or conversing with the content stored in the PKM (such as mem) or can be more integrated into the creation process (such as expand, augment this content). While this is the lowest hanging fruit form of integration, getting a great unstructured integration using AI requires more than just dumping embeddings into a prompt interface, something that many of the current apps do not seem to onboard for.
Render
Any personal knowledge management system is a dynamic ecosystem of practical and user-friendly structures. Within this system, you will usually find galleries, boards, timelines, groups (for example in Notion), and flashcards (for example in Anki). These structures serve as valuable resources, containing carefully curated knowledge that is easily accessible and interactive. Galleries act as personalized exhibition spaces, housing a collection of images, diagrams, and multimedia content that are visually appealing and intellectually stimulating. Boards function as brainstorming hubs, enabling you to organize various pieces of information, such as cards, notes, or snippets, in a way that mirrors the natural process of pinning ideas on a bulletin board.
Modify
Modification actions are essentially changes applied to your content - it could be as simple as editing a typo or deleting an unnecessary file. They could also be higher-level actions, such as marking a task complete or archiving an old document. Modification also has a deep integration with implicit processing, which is what makes processing so difficult to execute correctly. If you add a name to your meeting note attendees, it should record the new information, but now that changes related notes and unstructured consumption of information about this person.