
So, Notion's got these new site versions, right? And now we gotta think about whether to stick with Notion or go for something external. Let's break it down.
First up, pricing and domains. You need a Plus plan for custom domains, which is free for education but costs extra otherwise. Notion charges you $8 for the custom domain thing, and you get five sites or however many domains you want. Sounds cool, but it might be a pain if you're trying to host a bunch of project sites with custom domains. Webtrotion, works with Notion's free plan. You can host a site from a single database on GitHub Pages for free, which is neat but has its limits. And you can host on subpaths as well, aka, example.com/blog.
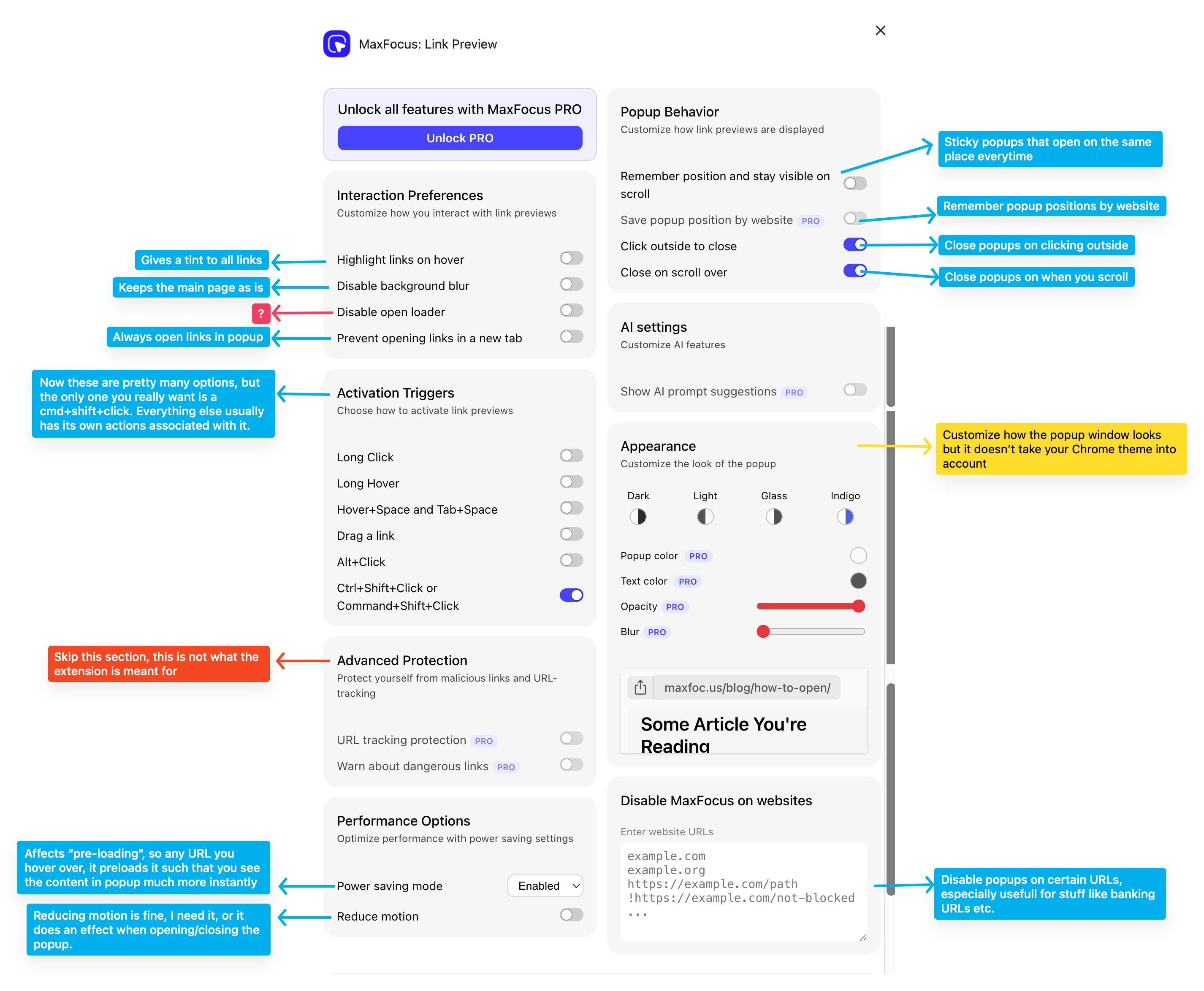
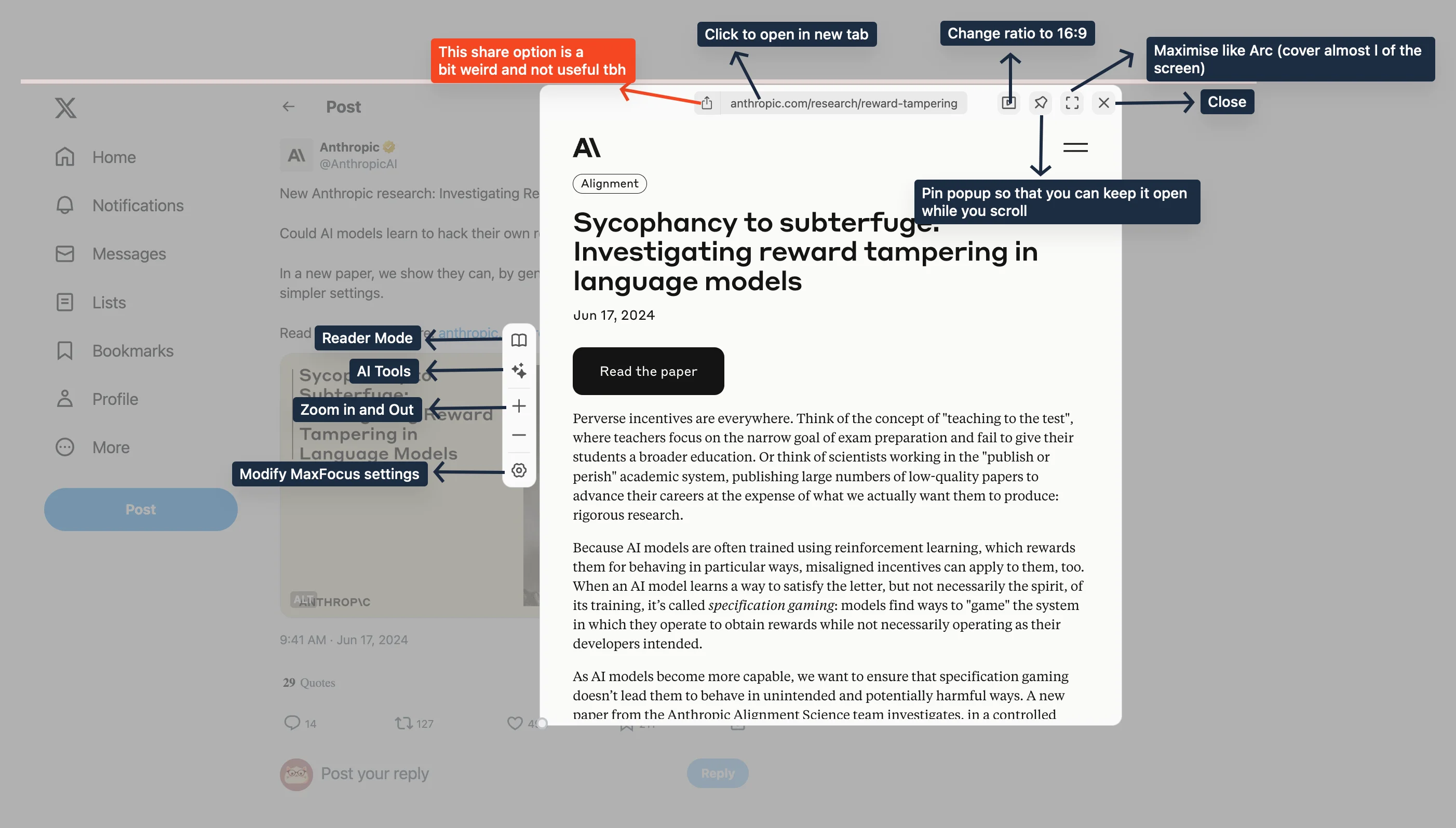
Notion sites are great if you want sub-pages inside posts, inline databases, table row colors, cropped images, post display options (Webtrotion has either a stream or a list view) or those fancy new preview cards. Webtrotion can't do that stuff unless you get into some complicated scraping business. But here's where Webtrotion shines: consistent URLs (Notion's URLs go crazy if you change titles), custom tag pages, no unnecessary property visibility, better custom headers, custom persistent footers, floating table of contents on mobile, stream view, custom styling, theming and colors, add html embeds, actually useful (sortable and searchable) simple tables and it can pull out references, block mentions, post comments using giscus (you need to be signed into Notion to comment), and even make RSS feeds. Oh, and it's got this cool Shiki transform for code blocks that I added recently.
When it comes to hosting and SEO, Webtrotion on GitHub Pages can be a bit iffy with Google indexing. Notion's got the upper hand here with their new Google Analytics and SEO stuff. But Webtrotion auto-generates those social media (OG) sharing images, while with Notion, you gotta do it manually every time. Update-wise, Notion sites are instant. Webtrotion on GitHub? Every eight hours, but you can tweak that to be 10 minutes, but not instant.
So, why am I sticking with Webtrotion? Because I want and prefer traditional website, and using Notion as my CMS. I want to be able to provide people with a URL and know where it lands, not having to worry about link rot, or add redirects, and change some fonts, pin posts etc. But honestly, it depends on what you need. I wish someday Notion lets us embed blocks into public websites. That'd be the best of both worlds.






![[Image version] And the outcome of the demo video above. Shows 3 entries, 2 of type debit, 1 of credit, across various inferred categories etc.](/_astro/Untitled.DG0K9Q9G_Z4hFdc.webp)