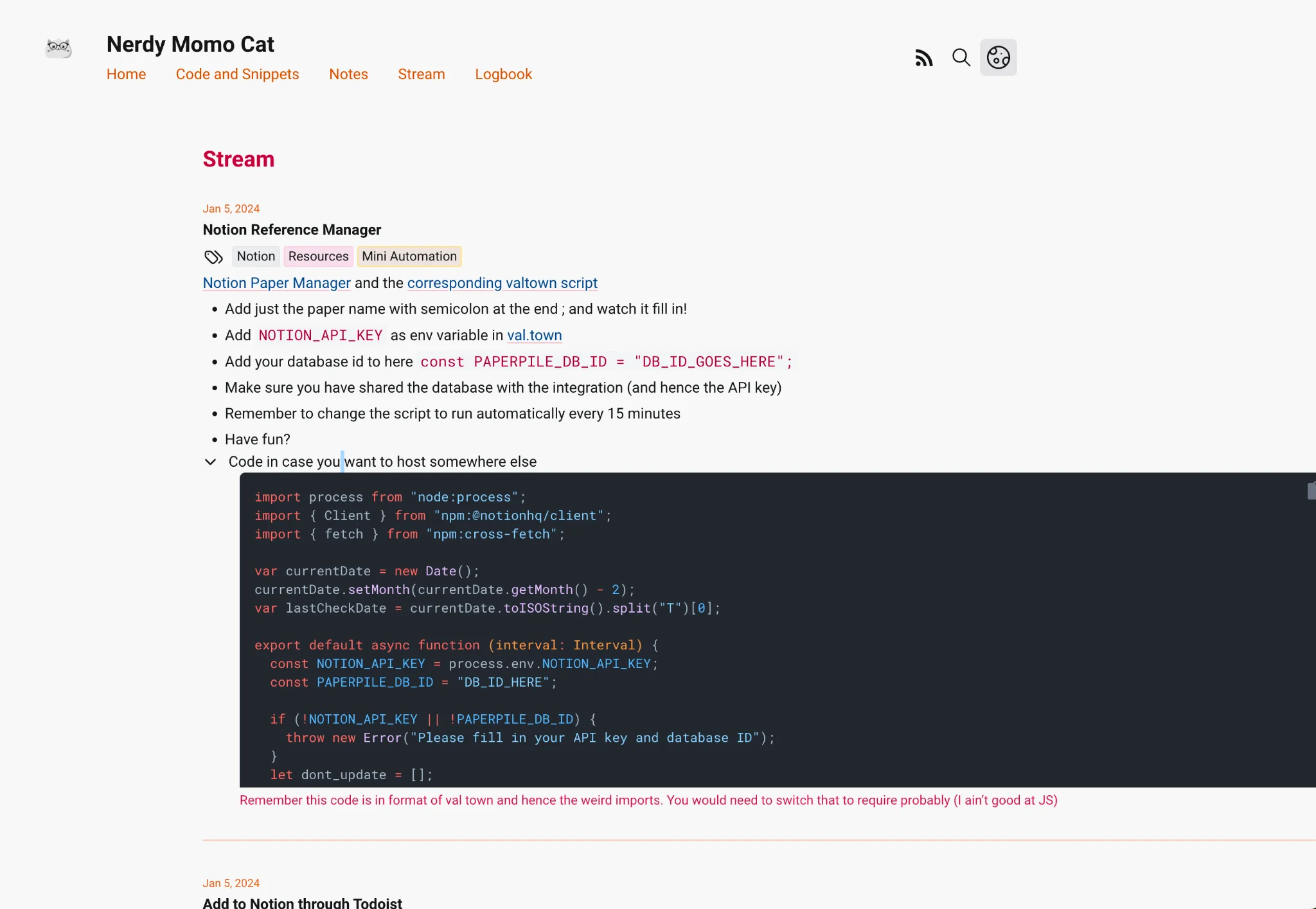
import process from "node:process";
import { Client } from "npm:@notionhq/client";
import { fetch } from "npm:cross-fetch";
var currentDate = new Date();
currentDate.setMonth(currentDate.getMonth() - 2);
var lastCheckDate = currentDate.toISOString().split("T")[0];
export default async function (interval: Interval) {
const NOTION_API_KEY = process.env.NOTION_API_KEY;
const PAPERPILE_DB_ID = "DB_ID_HERE";
if (!NOTION_API_KEY || !PAPERPILE_DB_ID) {
throw new Error("Please fill in your API key and database ID");
}
let dont_update = [];
const notion = new Client({ auth: NOTION_API_KEY });
const databaseId = PAPERPILE_DB_ID;
const queryResponse = await notion.databases.query({
database_id: databaseId,
page_size: 100,
filter: {
and: [
{
property: "Name",
rich_text: {
contains: ";",
},
},
{
property: "Created Time",
date: {
on_or_after: lastCheckDate,
},
},
],
},
});
const relevant_results = queryResponse.results.filter(
(i) => !dont_update.includes(i.id)
);
console.log(
`Checked database, found ${relevant_results.length} items to update.`
);
const all_updated = [];
for (var i of relevant_results) {
let semscholar_query = i.properties.Name.title[0].plain_text.replace(
/[^\w\s]/gi,
" "
); /*+ " " + i.properties["Author(s)"].multi_select.map(x => x.name).join(", ")*/
console.log(semscholar_query);
let fields = `url,title,abstract,authors,year,externalIds`;
const j = await fetch(
`https://api.semanticscholar.org/graph/v1/paper/search?query=${encodeURIComponent(
semscholar_query
)}&limit=1&fields=${encodeURIComponent(fields)}`
)
.then((r) => r.json())
.catch(function () {
console.log("Promise Rejected");
});
if (!(j.total > 0)) {
console.log("No results found for " + semscholar_query);
continue;
}
const paper = j.data[0];
// get bibtex
let all_external_ids = paper.externalIds;
// console.log(paper)
// console.log(all_external_ids)
let doi_to_add = null;
let bibtext_to_add = null;
if (paper.externalIds.DOI) {
doi_to_add = paper.externalIds.DOI;
} else if (paper.externalIds.PubMed) {
doi_to_add = paper.externalIds.PubMed;
} else if (paper.externalIds.PubMedCentral) {
doi_to_add = paper.externalIds.PubMedCentral;
} else if (paper.externalIds.ArXiv) {
doi_to_add = "arxiv." + paper.externalIds.ArXiv;
}
if (doi_to_add) {
// const bib = await fetch('https://api.paperpile.com/api/public/convert', {
// method: 'POST',
// headers: {
// 'Accept': 'application/json, text/plain, */*',
// 'Content-Type': 'application/json'
// },
// body: JSON.stringify({fromIds: true, input: doi_to_add.replace("arxiv.",""), targetFormat: "Bibtex"})
// }).then((r) => r.json());
// if (!(bib.error) && bib.withErrors==false)
// {
// bibtext_to_add=bib.output;
// if (bibtext_to_add.indexOf('abstract')!=-1)
// {bibtext_to_add = bibtext_to_add.split('abstract')[0]+ bibtext_to_add.split('abstract')[1].split('",').slice(1).join('",');}
// }
let bib = await fetch("https://doi.org/" + doi_to_add, {
method: "GET",
headers: {
Accept: "application/x-bibtex; charset=utf-8",
"Content-Type": "text/html; charset=UTF-8",
},
redirect: "follow",
}).then((r) => r.text());
// console.log(bib);
// if (!(bib.error) && bib.withErrors == false) {
// bibtext_to_add = bib;
// }
if (bib != "" && bib != null && bib.startsWith("@") == true) {
bib = bib.replace(/\$.*?\$/g, "");
bib = bib.replace(/amp/g, "");
bibtext_to_add = bib;
console.log("Found bib");
// console.log(bib)
}
} else {
let authors = [];
if (paper.authors != null) {
for (var jj = 0; jj < paper.authors.length; jj++) {
authors.push(paper.authors[jj].name);
}
}
console.log(authors.toString());
let bib_str =
"@article{" + paper.paperId + ",\n title = {" + paper.title + "},\n";
if (paper.venue != null && paper.venue != "") {
bib_str += "venue = {" + paper.venue + "},\n";
}
if (paper.year != null && paper.year != "") {
bib_str += " year = {" + paper.year + "},\n ";
}
if (paper.authors != null && paper.authors != []) {
bib_str += "author = {" + authors.join(" and ") + "}\n";
}
bib_str += "}";
console.log(bib_str);
bibtext_to_add = bib_str;
}
// get tldr from semantic scholar
let sem_scholar_ppid = paper.paperId;
let tldr = null;
const tl_f = await fetch(
`https://api.semanticscholar.org/graph/v1/paper/${encodeURIComponent(
sem_scholar_ppid
)}?fields=${encodeURIComponent("tldr")}`
).then((r) => r.json());
if (tl_f.tldr) {
tldr = tl_f.tldr.text;
}
let updateOptions = {
page_id: i.id,
properties: {
Name: {
title: [
{
type: "text",
text: {
content:
paper.title ||
i.properties.Name.title[0].plain_text.replace(";", ""),
},
},
],
},
Authors: {
multi_select: paper.authors
.filter((x) => x)
.map((x) => ({
name: x.name.replace(",", ""),
}))
.slice(0, 100),
},
Abstract: {
rich_text: [
{
text: {
content:
(paper.abstract || "").length < 1900
? paper.abstract || ""
: paper.abstract.substring(0, 1900) + "...",
},
},
],
},
Link: {
url: paper.url,
},
Year: {
number: paper.year,
},
},
};
if (tldr) {
updateOptions.properties.tldr = {
rich_text: [
{
text: {
content: tldr,
},
},
],
};
}
if (doi_to_add) {
updateOptions.properties.DOI = {
rich_text: [
{
text: {
content: doi_to_add,
},
},
],
};
}
if (bibtext_to_add) {
updateOptions.properties.Bibtex = {
rich_text: [
{
text: {
content: bibtext_to_add,
},
},
],
};
if (bibtext_to_add != "") {
updateOptions.properties.In_Text_Citation = {
rich_text: [
{
text: {
content: bibtext_to_add.split("{")[1].split(",")[0],
},
},
],
};
}
}
try {
await notion.pages.update(updateOptions);
all_updated.push(i.properties.Name.title[0].plain_text);
} catch (e) {
console.error(`Error on ${i.id}: [${e.status}] ${e.message}`);
if (e.status == 409) {
console.log("Saving conflict, scheduling retry in 3 seconds");
setTimeout(async () => {
try {
console.log(`Retrying ${i.id}`);
await notion.pages.update(updateOptions);
} catch (e) {
console.error(
`Subsequent error while resolving saving conflict on ${i.id}: [${e.status}] ${e.message}`
);
// dont_update.push(i.id);
}
}, 3000);
} else {
// dont_update.push(i.id);
}
}
console.log("Updated " + i.properties.Name.title[0].plain_text);
}
}
Remember this code is in format of val town and hence the weird imports. You would need to switch that to require probably (I ain’t good at JS)